decoding strategies, text generation, GPT-2, token probabilities
Introduction
This assignment explores how different decoding strategies affect text generated by GPT-2 when completing teacher feedback prompts. We compare greedy search, beam search, top-k sampling, and nucleus (top-p) sampling, analyzing token-level probability behavior and discussing implications for classroom use.
Set Up and Short Explanation
What GPT-2 does during generation: GPT-2 is an autoregressive language model. Given a sequence of tokens, it predicts a probability distribution over the entire vocabulary for the next token. It then selects a token from that distribution, appends it to the sequence, and repeats. Text is generated one token at a time.
Logits and probabilities: At each generation step, the model outputs a vector of raw scores called logits—one per vocabulary token. These are not probabilities yet. Applying the softmax function converts logits into a valid probability distribution (values between 0 and 1 that sum to 1). A token with a high probability is one the model considers likely given the preceding context.
Why decoding matters: The same model with the same prompt can produce very different text depending on how we select the next token from the probability distribution. A deterministic strategy always picks the top token, while sampling strategies introduce randomness. This choice directly affects whether the output is repetitive, creative, coherent, or surprising—all of which matter when generating text for educational settings like teacher feedback.
# Install compatible dependencies (only runs if transformers is not yet installed)import importlib.utilif importlib.util.find_spec("transformers") isNone:import subprocess subprocess.check_call(["pip", "install","transformers>=4.30,<5", "torch", "matplotlib", "numpy", "pandas","-q" ])import osos.environ["TF_CPP_MIN_LOG_LEVEL"] ="3"# Suppress TensorFlow info messagesimport torchimport numpy as npimport matplotlib.pyplot as pltimport pandas as pdfrom transformers import GPT2LMHeadModel, GPT2Tokenizer# Load model and tokenizertokenizer = GPT2Tokenizer.from_pretrained('gpt2')model = GPT2LMHeadModel.from_pretrained('gpt2')_ = model.eval()device ='cuda'if torch.cuda.is_available() else'cpu'model = model.to(device)# Set pad token to eos token (GPT-2 has no pad token by default)tokenizer.pad_token = tokenizer.eos_tokenmodel.config.pad_token_id = tokenizer.eos_token_id# Reproducibility_ = torch.manual_seed(42)np.random.seed(42)print(f"Model loaded on: {device}")print(f"Vocabulary size: {tokenizer.vocab_size:,}")
Model loaded on: cpu
Vocabulary size: 50,257
Prompt Family: Teacher Feedback
We use a family of three prompts that simulate teacher feedback on student essays. These prompts are educationally relevant because feedback is one of the most common and impactful uses of language in classrooms. Each prompt begins a feedback sentence that the model must complete, letting us observe how different decoding strategies shape the tone, specificity, and coherence of the generated feedback.
prompts = ["Teacher feedback on a student essay: Your claim is interesting, but","Teacher feedback on a student essay: You are close, but your reasoning needs","Teacher feedback on a student essay: One thing to revise in this paragraph is",]for i, p inenumerate(prompts, 1):print(f"Prompt {i}: \"{p}\"")
Prompt 1: "Teacher feedback on a student essay: Your claim is interesting, but"
Prompt 2: "Teacher feedback on a student essay: You are close, but your reasoning needs"
Prompt 3: "Teacher feedback on a student essay: One thing to revise in this paragraph is"
def generate_and_analyze(prompt, **generate_kwargs):""" Generate text from a prompt using model.generate() with output_scores=True. Returns the generated text, list of token strings, and their probabilities. Uses compute_transition_scores() to correctly handle beam search reordering. """ input_ids = tokenizer.encode(prompt, return_tensors='pt').to(device) attention_mask = torch.ones_like(input_ids)with torch.no_grad(): outputs = model.generate( input_ids, attention_mask=attention_mask, pad_token_id=tokenizer.eos_token_id, max_new_tokens=50, output_scores=True, return_dict_in_generate=True,**generate_kwargs )# Get the generated token IDs (excluding the prompt) generated_ids = outputs.sequences[0, input_ids.shape[1]:]# Use compute_transition_scores to get log-probs aligned to the final sequence.# This correctly handles beam reordering, unlike manually indexing outputs.scores. num_beams = generate_kwargs.get('num_beams', 1) transition_scores = model.compute_transition_scores( outputs.sequences, outputs.scores, outputs.beam_indices if num_beams >1elseNone, normalize_logits=True, )# transition_scores are log-probabilities; convert to probabilities token_probs = torch.exp(transition_scores[0]).tolist() tokens = [tokenizer.decode([tid]) for tid in generated_ids] probabilities = token_probs[:len(tokens)] generated_text = tokenizer.decode(outputs.sequences[0], skip_special_tokens=True)return generated_text, tokens, probabilitiesdef plot_token_probabilities(tokens, probabilities, title):""" Bar chart of per-token probabilities, color-coded by confidence level. Uses colorblind-friendly palette (Wong, 2011). """ fig, ax = plt.subplots(figsize=(14, 4))# Colorblind-friendly palette (Wong, 2011) colors = []for p in probabilities:if p >=0.7: colors.append('#0072B2') # blue — high confidenceelif p >=0.3: colors.append('#E69F00') # amber — moderateelse: colors.append('#D55E00') # vermillion — low confidence x_positions =range(len(tokens)) ax.bar(x_positions, probabilities, color=colors, edgecolor='white', linewidth=0.5)# Clean up token labels for display display_tokens = [t.replace('\n', '\\n') for t in tokens] ax.set_xticks(x_positions) ax.set_xticklabels(display_tokens, rotation=60, ha='right', fontsize=8) ax.set_ylabel('Probability') ax.set_title(title) ax.set_ylim(0, 1.05) ax.axhline(y=0.5, color='gray', linestyle='--', alpha=0.3)# Legendfrom matplotlib.patches import Patch legend_elements = [ Patch(facecolor='#0072B2', label='High (>= 0.7)'), Patch(facecolor='#E69F00', label='Moderate (0.3–0.7)'), Patch(facecolor='#D55E00', label='Low (< 0.3)'), ] ax.legend(handles=legend_elements, loc='upper right', fontsize=8) plt.tight_layout() plt.show()def display_results(prompt, generated_text, tokens, probabilities):""" Display the prompt, generated continuation, and probability summary. """ continuation = generated_text[len(prompt):]print(f"Prompt: \"{prompt}\"")print(f"Continuation: \"{continuation.strip()}\"")print(f"Avg token probability: {np.mean(probabilities):.3f}")print(f"Min token probability: {np.min(probabilities):.3f}")print()
Greedy Search
How it works: At each step, greedy search selects the single token with the highest probability. It is deterministic; the same prompt always produces the same output. That determinism makes it predictable and consistent, but it can lead to repetitive or generic text because it never explores lower-probability alternatives that might produce more natural language.
======================================================================
GREEDY SEARCH
======================================================================
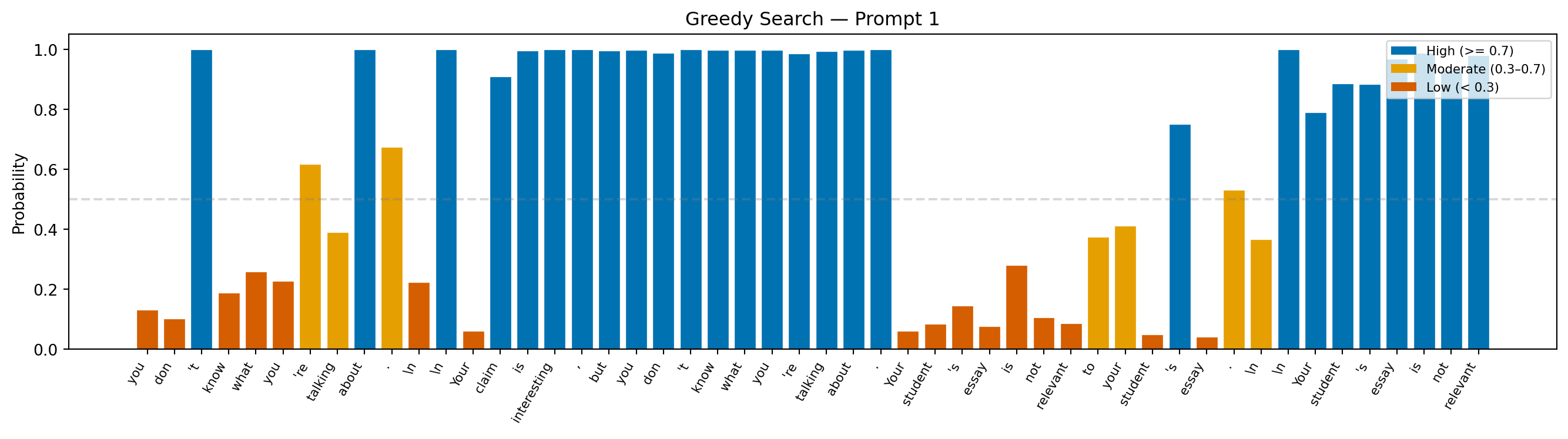
--- Prompt 1 ---
Prompt: "Teacher feedback on a student essay: Your claim is interesting, but"
Continuation: "you don't know what you're talking about.
Your claim is interesting, but you don't know what you're talking about. Your student's essay is not relevant to your student's essay.
Your student's essay is not relevant"
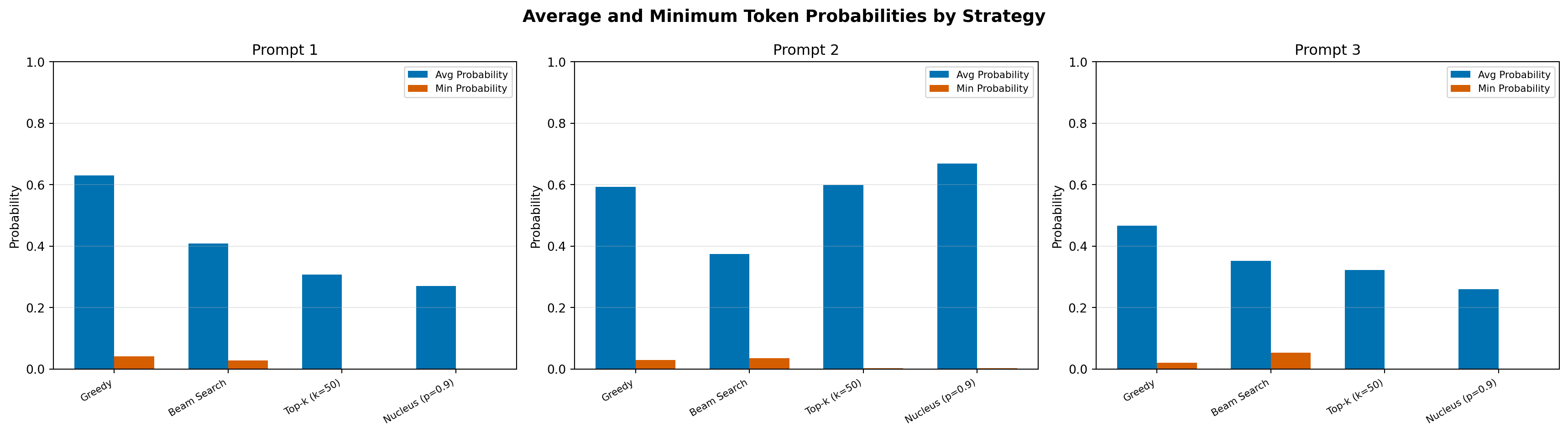
Avg token probability: 0.630
Min token probability: 0.042
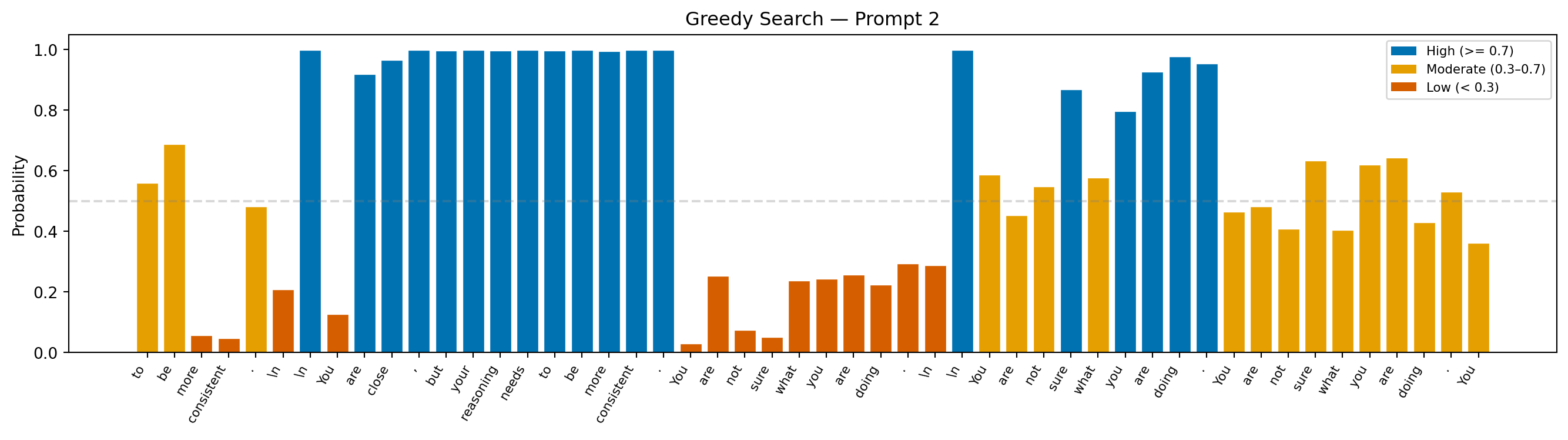
--- Prompt 2 ---
Prompt: "Teacher feedback on a student essay: You are close, but your reasoning needs"
Continuation: "to be more consistent.
You are close, but your reasoning needs to be more consistent. You are not sure what you are doing.
You are not sure what you are doing. You are not sure what you are doing. You"
Avg token probability: 0.593
Min token probability: 0.030
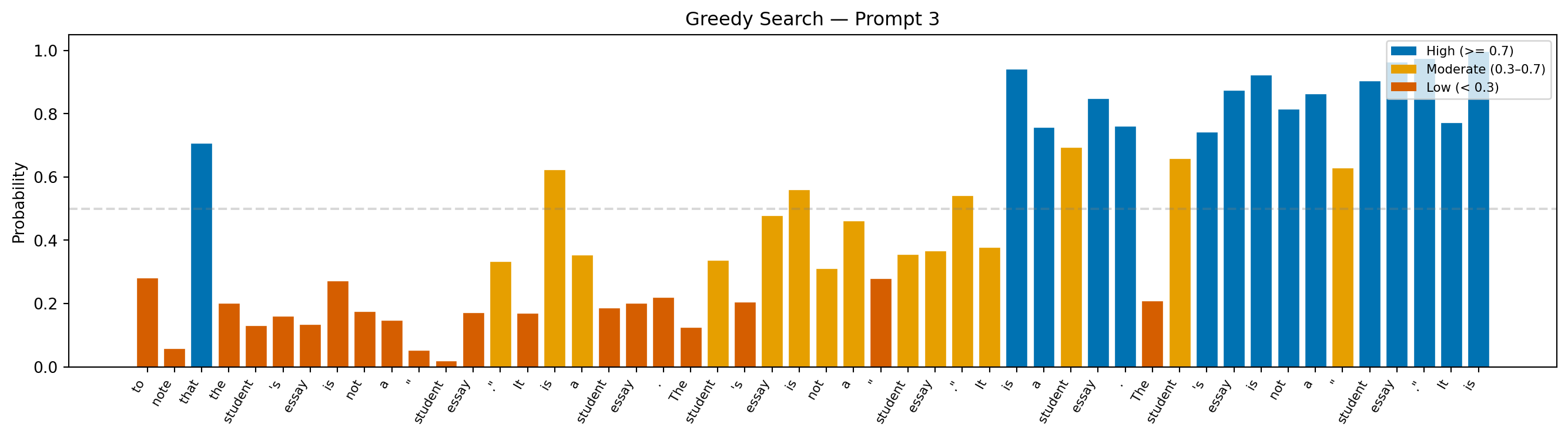
--- Prompt 3 ---
Prompt: "Teacher feedback on a student essay: One thing to revise in this paragraph is"
Continuation: "to note that the student's essay is not a "student essay." It is a student essay. The student's essay is not a "student essay." It is a student essay. The student's essay is not a "student essay." It is"
Avg token probability: 0.467
Min token probability: 0.020
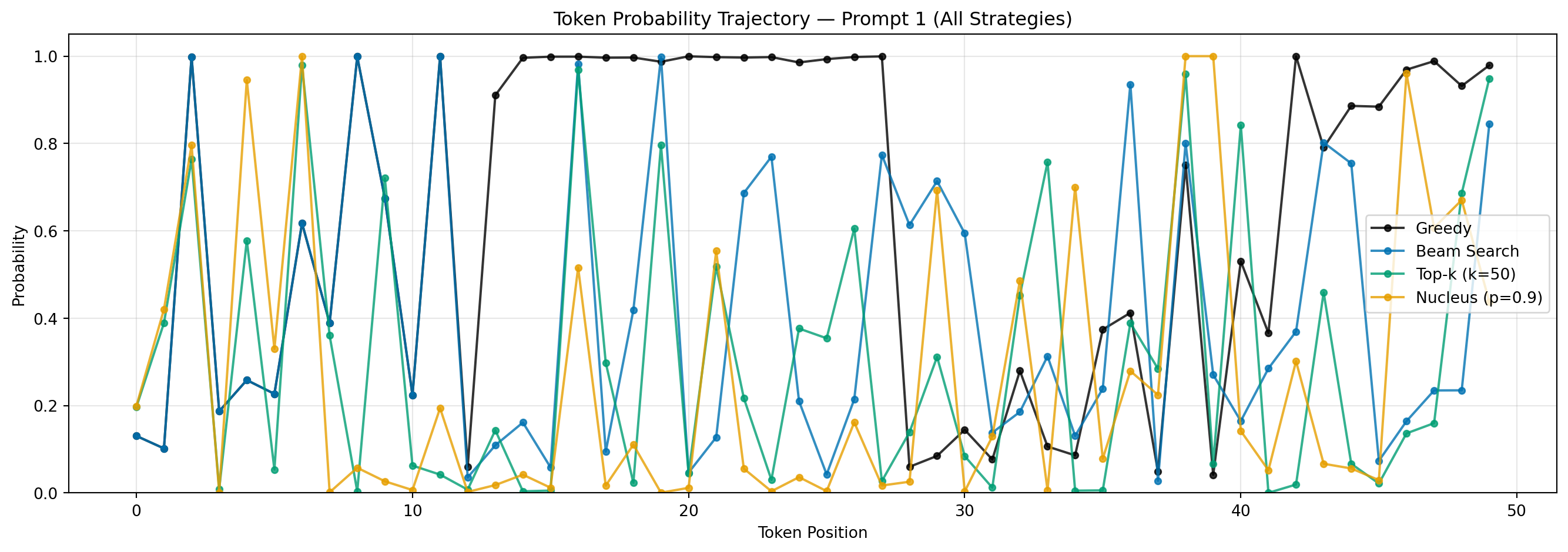
Interpretation: Because greedy search always selects the single most probable token, probability bars stay moderate-to-high throughout, but this confidence comes at a cost: the model can lock into repetitive loops with no mechanism to escape them.
Beam Search
How it works: Beam search maintains multiple candidate sequences (“beams”) in parallel. At each step, it expands each beam with the top candidates and keeps only the highest-scoring sequences overall. The final output is the sequence with the best cumulative score. Beam search often produces more globally coherent text than greedy search. We also use no_repeat_ngram_size=2 to prevent the model from repeating the same bigram, which helps reduce the repetitive loops that GPT-2 is prone to.
======================================================================
BEAM SEARCH (num_beams=5, no_repeat_ngram_size=2)
======================================================================
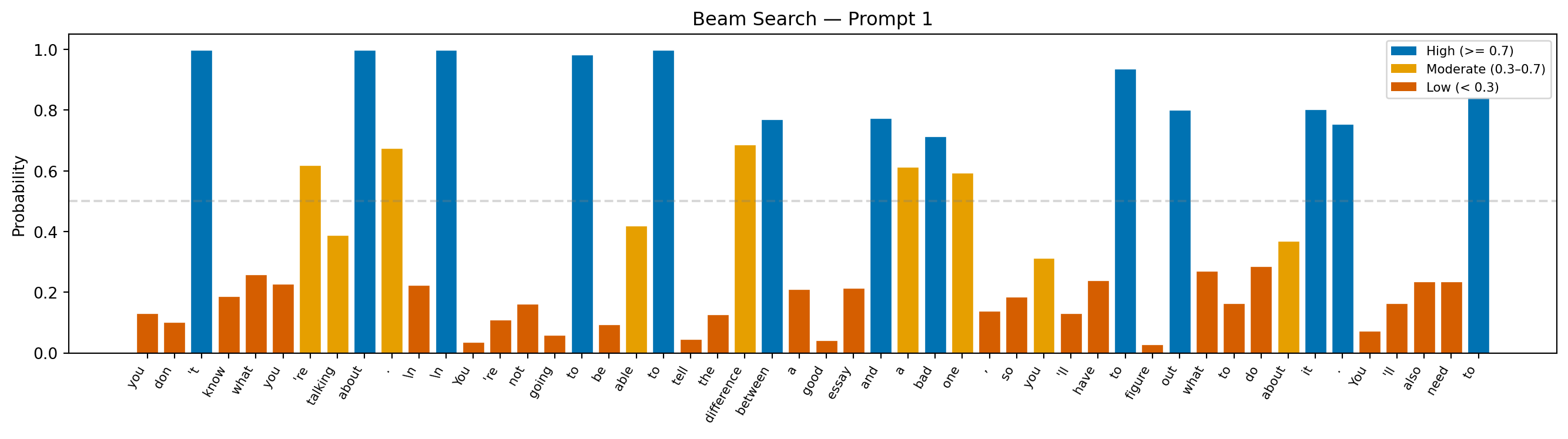
--- Prompt 1 ---
Prompt: "Teacher feedback on a student essay: Your claim is interesting, but"
Continuation: "you don't know what you're talking about.
You're not going to be able to tell the difference between a good essay and a bad one, so you'll have to figure out what to do about it. You'll also need to"
Avg token probability: 0.409
Min token probability: 0.028
--- Prompt 2 ---
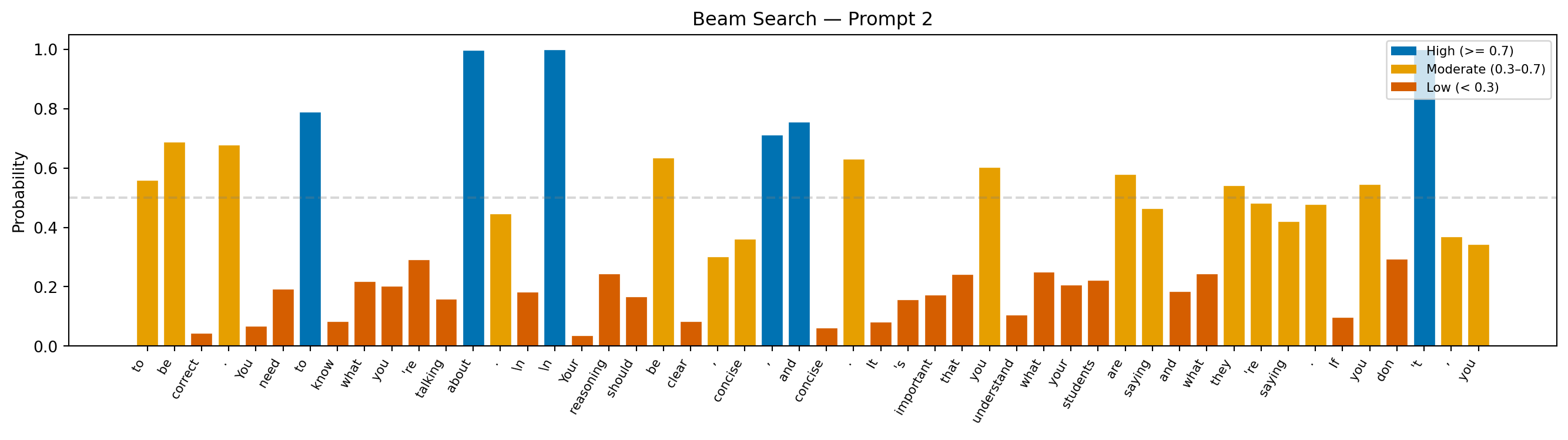
Prompt: "Teacher feedback on a student essay: You are close, but your reasoning needs"
Continuation: "to be correct. You need to know what you're talking about.
Your reasoning should be clear, concise, and concise. It's important that you understand what your students are saying and what they're saying. If you don't, you"
Avg token probability: 0.374
Min token probability: 0.035
--- Prompt 3 ---
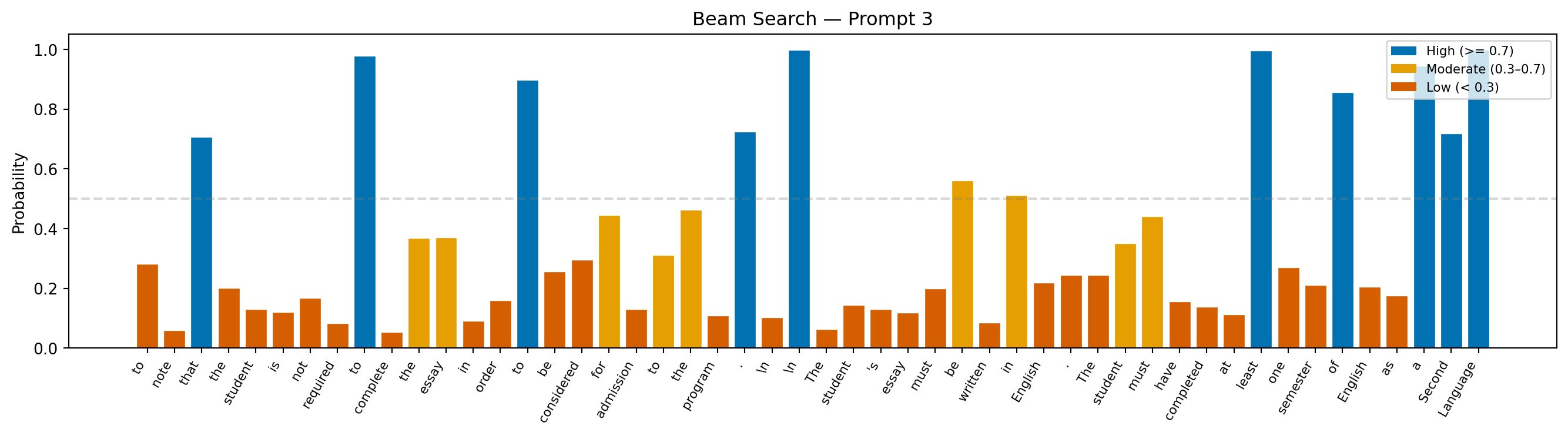
Prompt: "Teacher feedback on a student essay: One thing to revise in this paragraph is"
Continuation: "to note that the student is not required to complete the essay in order to be considered for admission to the program.
The student's essay must be written in English. The student must have completed at least one semester of English as a Second Language"
Avg token probability: 0.352
Min token probability: 0.053
Interpretation: The probability trace here tells a revealing story: most tokens are chosen confidently, but occasional dips mark moments where the no-repeat constraint forced the model away from its top prediction. Those dips are the price of avoiding the loops greedy search falls into.
Top-k Sampling
How it works: At each step, top-k sampling restricts the candidate pool to the k most probable tokens, then samples randomly from that reduced distribution. Top-k sampling introduces variety while preventing the model from selecting extremely unlikely tokens. A lower temperature sharpens the distribution, making higher-probability tokens more likely to be chosen while still allowing some diversity.
--- Prompt 1 ---
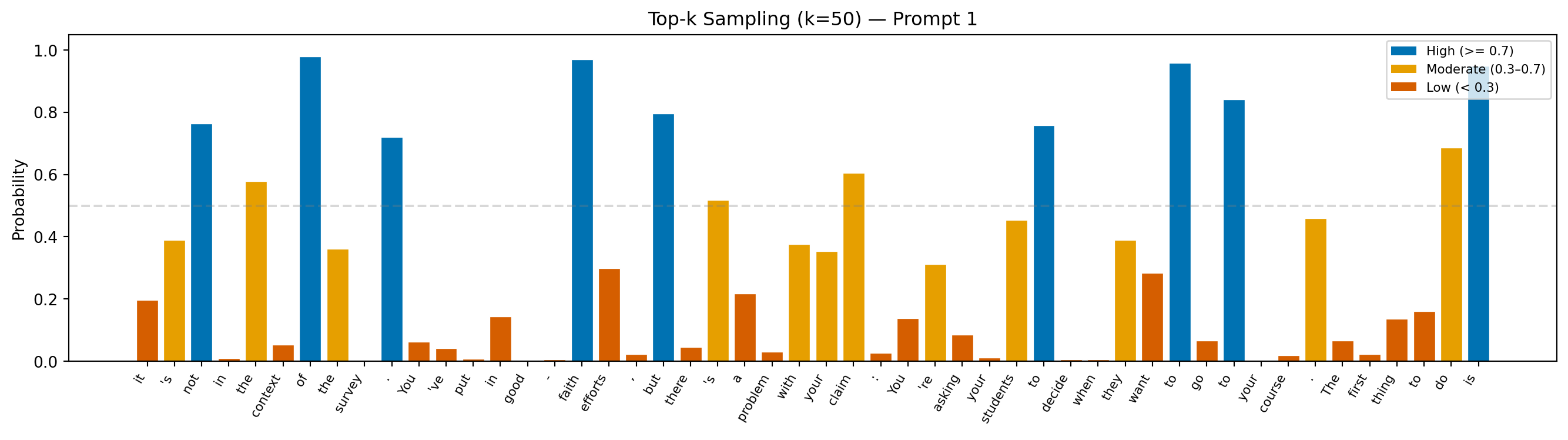
Prompt: "Teacher feedback on a student essay: Your claim is interesting, but"
Continuation: "it's not in the context of the survey. You've put in good-faith efforts, but there's a problem with your claim: You're asking your students to decide when they want to go to your course. The first thing to do is"
Avg token probability: 0.308
Min token probability: 0.000
--- Prompt 2 ---
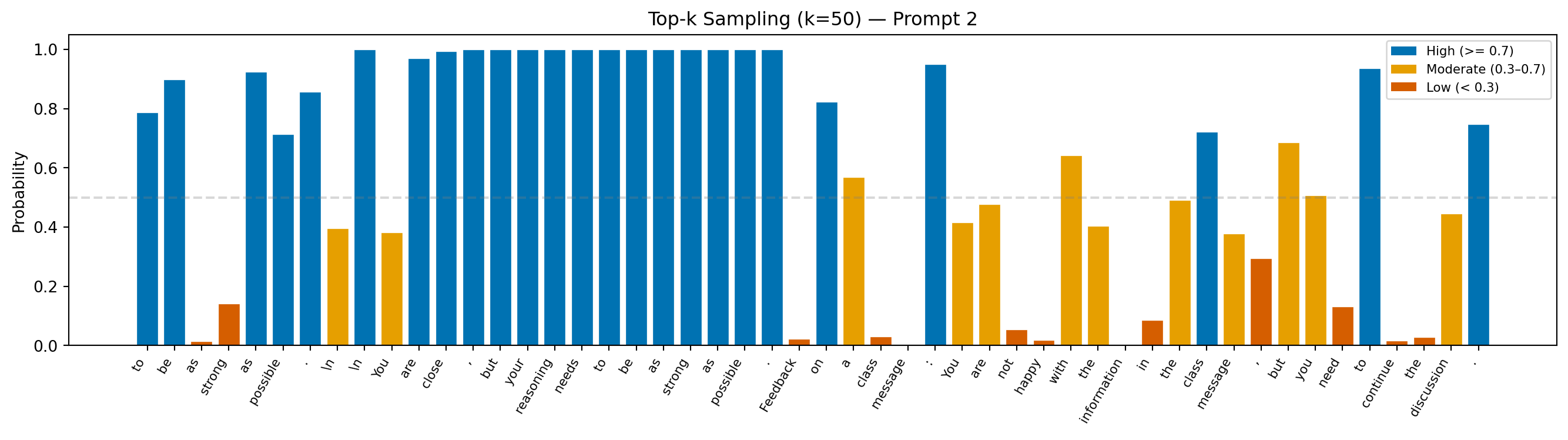
Prompt: "Teacher feedback on a student essay: You are close, but your reasoning needs"
Continuation: "to be as strong as possible.
You are close, but your reasoning needs to be as strong as possible. Feedback on a class message: You are not happy with the information in the class message, but you need to continue the discussion."
Avg token probability: 0.599
Min token probability: 0.003
--- Prompt 3 ---
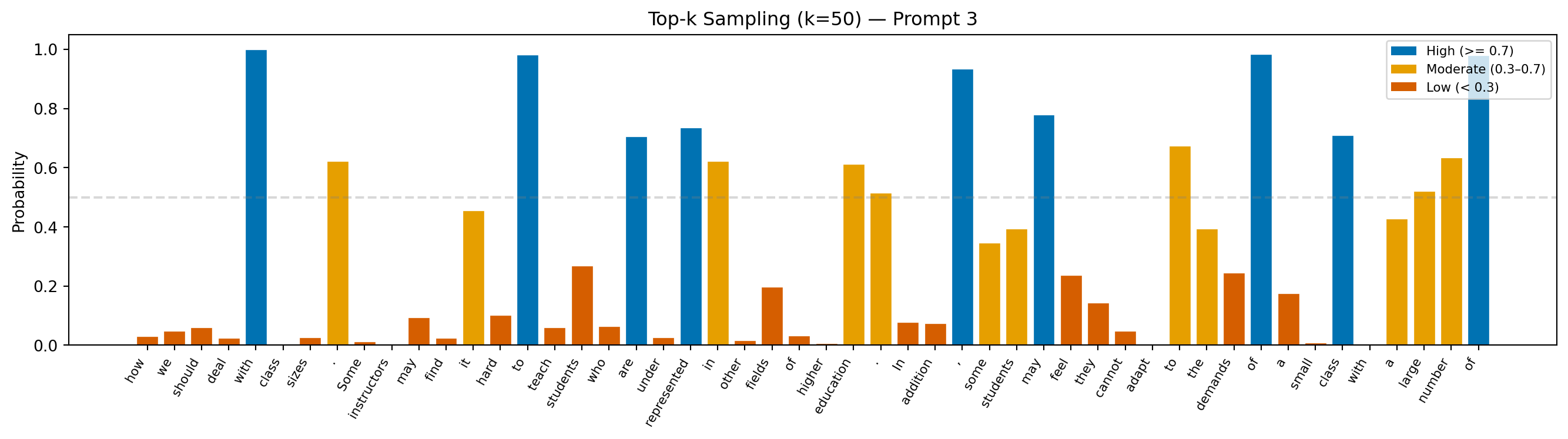
Prompt: "Teacher feedback on a student essay: One thing to revise in this paragraph is"
Continuation: "how we should deal with class sizes. Some instructors may find it hard to teach students who are underrepresented in other fields of higher education. In addition, some students may feel they cannot adapt to the demands of a small class with a large number of"
Avg token probability: 0.323
Min token probability: 0.002
Interpretation: Token probabilities run lower here than in greedy or beam, not because the model is confused, but because it is sometimes deliberately passing over its top prediction in favor of a plausible alternative. That trade-off is what produces more varied, natural-sounding text.
Nucleus (Top-p) Sampling
How it works: Nucleus sampling dynamically adjusts the candidate pool at each step. Instead of a fixed number of tokens (top-k), it includes the smallest set of tokens whose cumulative probability exceeds a threshold p. When the model is confident (one token dominates), the pool is small; when the model is uncertain (many tokens share probability), the pool is larger, which adapts to the model’s confidence at each position, making it particularly effective at producing natural-sounding text.
--- Prompt 1 ---
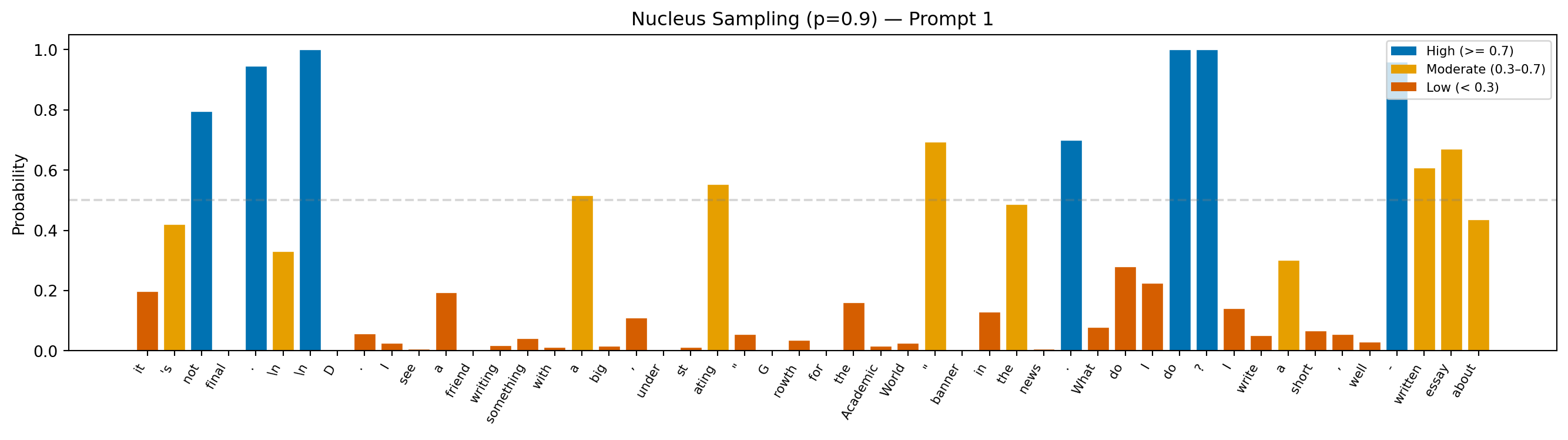
Prompt: "Teacher feedback on a student essay: Your claim is interesting, but"
Continuation: "it's not final.
D. I see a friend writing something with a big, understating "Growth for the Academic World" banner in the news. What do I do? I write a short, well-written essay about"
Avg token probability: 0.270
Min token probability: 0.001
--- Prompt 2 ---
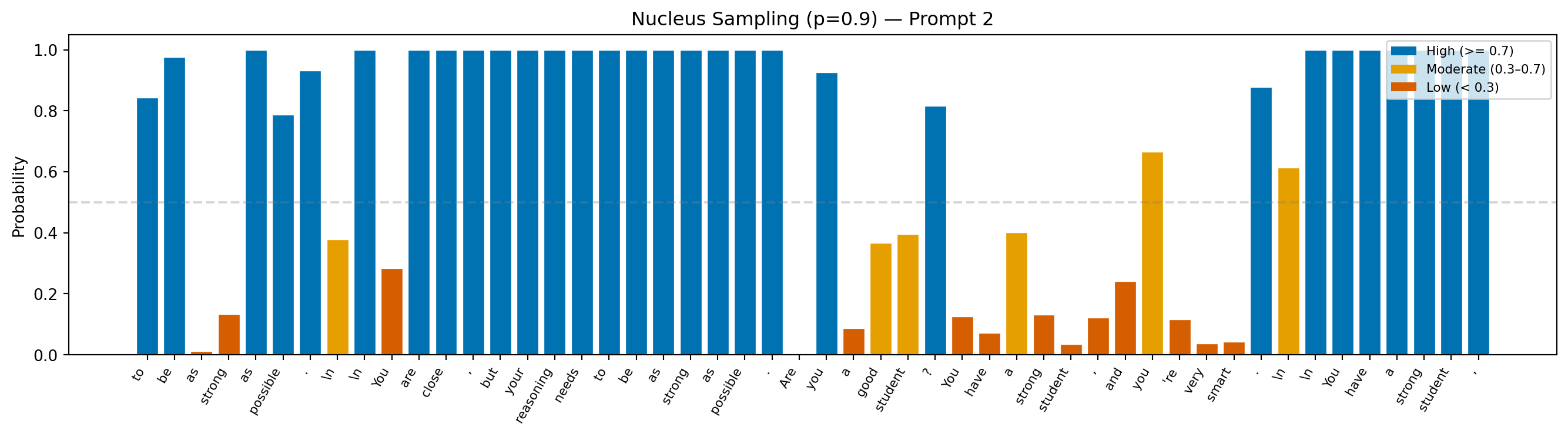
Prompt: "Teacher feedback on a student essay: You are close, but your reasoning needs"
Continuation: "to be as strong as possible.
You are close, but your reasoning needs to be as strong as possible. Are you a good student? You have a strong student, and you're very smart.
You have a strong student,"
Avg token probability: 0.668
Min token probability: 0.002
--- Prompt 3 ---
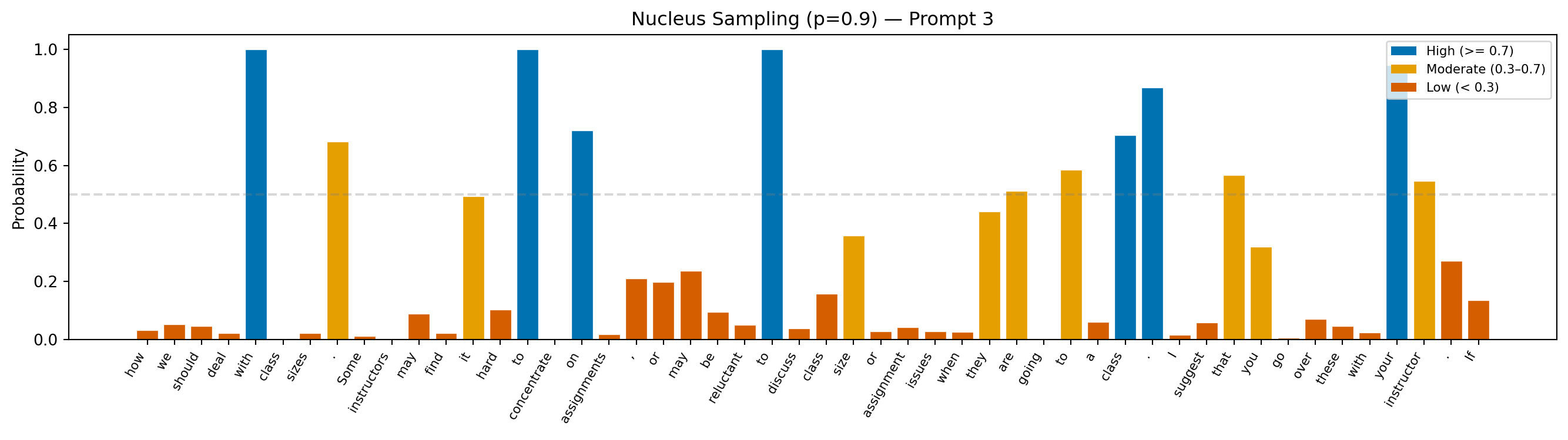
Prompt: "Teacher feedback on a student essay: One thing to revise in this paragraph is"
Continuation: "how we should deal with class sizes. Some instructors may find it hard to concentrate on assignments, or may be reluctant to discuss class size or assignment issues when they are going to a class. I suggest that you go over these with your instructor. If"
Avg token probability: 0.260
Min token probability: 0.002
Interpretation: The dynamic pool is nucleus sampling’s defining feature. When the model is confident, the pool shrinks, and probabilities stay high; when uncertainty spreads across many tokens, the pool expands. The result is text that stays coherent without becoming formulaic.
Comparison and Interpretation
Side-by-Side Summary
The table and visualization below compare outputs across all four decoding strategies.
Key observations to look for:
Naturalness: Which outputs read most like real teacher feedback? Sampling strategies (top-k, nucleus) tend to produce more varied, human-like phrasing, while deterministic strategies (greedy, beam) can sound formulaic.
Repetition: Greedy search is especially prone to repetitive loops (e.g., repeating the same phrase). Beam search with n-gram blocking mitigates this, but can still feel rigid. Sampling strategies largely avoid repetition due to randomness.
Coherence: Beam search often produces the most globally coherent text because it optimizes the full sequence score. Sampling strategies may occasionally generate surprising or off-topic tokens.
Token probability stability: Greedy search shows consistently high probabilities (always picking the top token). Beam search shows occasional dips where the no-repeat constraint forces less likely tokens. Sampling strategies show more variable probabilities throughout, reflecting their random exploration of the distribution.
Classroom implications: For teacher feedback tools, we need a balance between consistency (so feedback is always appropriate) and naturalness (so feedback does not sound robotic). Very low-probability tokens may signal incoherent or off-topic text, which would be inappropriate in a classroom.
======================================================================
COMPARISON TABLE — Prompt 1
======================================================================
Strategy Generated Feedback Avg Prob Min Prob
Greedy you don't know what you're talking about.\n\nYour claim is interesting, but you don't know what you're talking about. Your... 0.630 0.042
Beam Search you don't know what you're talking about.\n\nYou're not going to be able to tell the difference between a good essay and a... 0.409 0.028
Top-k (k=50) it's not in the context of the survey. You've put in good-faith efforts, but there's a problem with your claim: You're a... 0.308 0.000
Nucleus (p=0.9) it's not final.\n\nD. I see a friend writing something with a big, understating "Growth for the Academic World" banner in ... 0.270 0.001
Classroom Recommendation
Which decoding strategy should a classroom feedback tool use?
Based on the generated text and token-level probability evidence above, my recommendation is:
Use nucleus (top-p) sampling with conservative parameters (p=0.9, temperature=0.7–0.8).
Here is my reasoning:
Greedy search produces the highest average token probabilities, meaning the model is maximally confident at each step. However, the outputs tend to be repetitive and generic, characteristics that would make automated teacher feedback feel robotic and unhelpful to students. Feedback that repeats the same phrases loses its instructional value.
Beam search improves coherence by optimizing the full sequence and avoids exact repetition with n-gram blocking. It is a good middle ground, but the outputs can still feel formulaic and lack the varied phrasing that characterizes effective human feedback.
Top-k sampling introduces controlled variety, but a fixed k means the candidate pool does not adapt to the model’s confidence. At positions where the model is very certain (e.g., after “Your claim is interesting, but”), allowing 50 candidates introduces unnecessary noise. At positions where the model is uncertain, k=50 might not be enough.
Nucleus sampling adapts naturally to the model’s confidence at each step. When the model has a clear next token, the pool shrinks, maintaining coherence. When multiple plausible continuations exist, the pool expands, enabling natural variety. This dynamic balance produces feedback that sounds more human-written while staying on-topic.
Trade-offs for classroom use
Consideration
Best Strategy
Consistency (same prompt → same output)
Greedy or Beam (deterministic)
Naturalness (sounds like a real teacher)
Nucleus or Top-k (sampling)
Safety (avoids inappropriate content)
Beam > Nucleus > Top-k > Greedy
Variety (different feedback each time)
Top-k or Nucleus
For a production classroom tool, nucleus sampling with a moderate temperature and post-generation filtering (to catch any inappropriate outputs) offers the best balance of natural-sounding, varied, and coherent teacher feedback. If consistency is paramount (e.g., high-stakes assessments), beam search would be the safer choice.
The token-level probability evidence supports this: nucleus sampling maintains reasonably stable probabilities (indicating coherent text) while showing enough variation to avoid the monotonous repetition visible in greedy search outputs.
Declaration of Generative AI Utilization
During the preparation of this work, the author utilized Anthropic’s Claude Opus 4.6. The author reviewed and edited the content of this assignment as needed and takes full responsibility for it.